Decision Trees
How complex decisions can be divided & conquered
Decision tree is a classification technique. Recursive nature of the decision tree makes it easier to reason out about the problem and how this technique solves it.
Let's look at the structure of the decision tree.
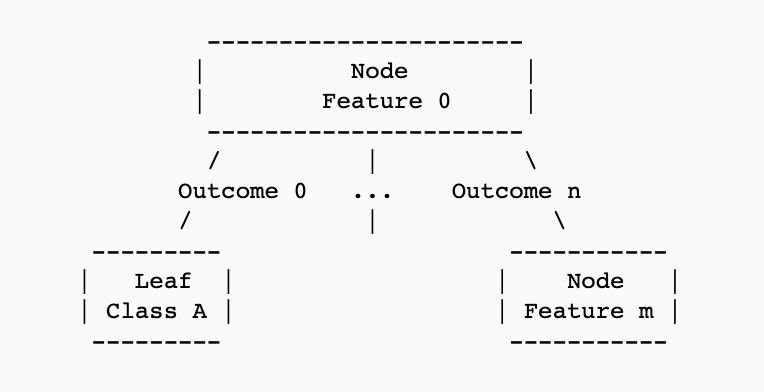
- Each node represents a feature to be evaluated.
- Each edge from that node represents the outcomes of evaluating the feature.
- Each leaf node represents the class label.
Decision trees can be used for regression tasks and for multi-class classification tasks. But here we consider only binary classification.
Training a Decision Tree Classifier
The training set consists of instances represented by feature vectors labelled into either A or B.
At each node, we select a feature to split the training set such that the Information Gain is maximised. When we reach a point where a node only contains a homogenious set of instances (i.e. all instances that reached that node are either class A or class B) we stop further splitting. This is also called the purity of the split.
Information Gain = Entropy Before Split - Entropy After Split
Entropy measures the impurity of the split and is quantified for binary classes A,B as:

So in general at any node
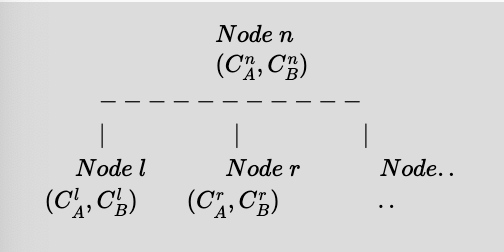
$(C^n_B,C^n_B)$ are the training set data instance counts of classes A and B respectively at node $n$. Similarly $(C^l_B,C^l_B)$ at node $l$ and $(C^r_B,C^r_B)$ at node $r$. Considering a binary split:

Since we recursively split the training set, $C^n_A = C^l_A + C^r_A$ and $C^n_B = C^l_B + C^r_B$

Entropies are weighted according to the ratio of instances that goes to each side.
This process is repeated for each of the features available yielding a set of Information Gains per each candidate feature.
In general for k features:
Best split Feature Index = ArgMax(InformationGain_F0, ... ,InformationGain_Fk)
For example here's a training set
| Name | EyeColor | PlayCricket | Education | Class |
|---|---|---|---|---|
| Apu | green | true | UG | A |
| Bernice | blue | false | PG | B |
| Carl | green | true | UG | A |
| Doris | brown | false | PG | B |
| Edna | blue | false | PG | B |
| Frink | brown | true | PG | B |
| Gil | brown | true | UG | B |
| Homer | blue | true | UG | A |
| Itchy | blue | true | PG | A |
Let's evaluate the training set on the feature 'EyeColor'
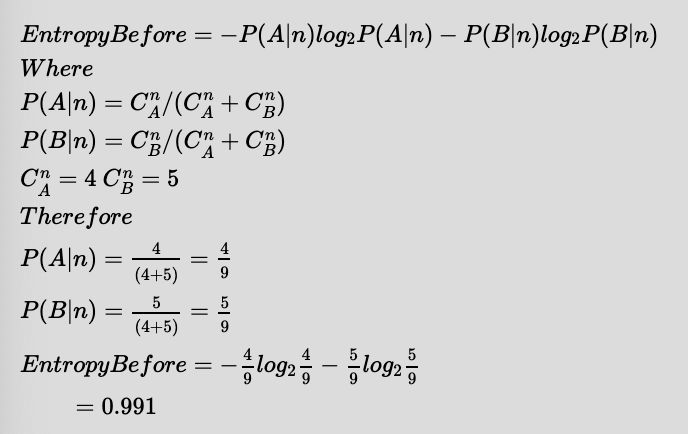
EyeColor feature, splits the training set into 3, one for each outcome of {green,blue,brown} resulting in 3 potential nodes.
Feature (EyeColor)
____________|______________
| | |
Green = 2 Blue = 4 Brown = 3
(A=2,B=0) (A=2,B=2) (A=0,B=3)
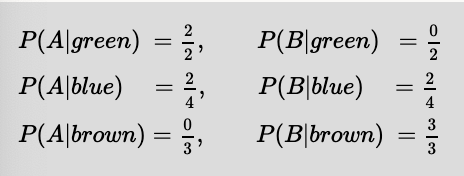
Entropies for each outcome

Therefore EntropyAfter can be computed as below
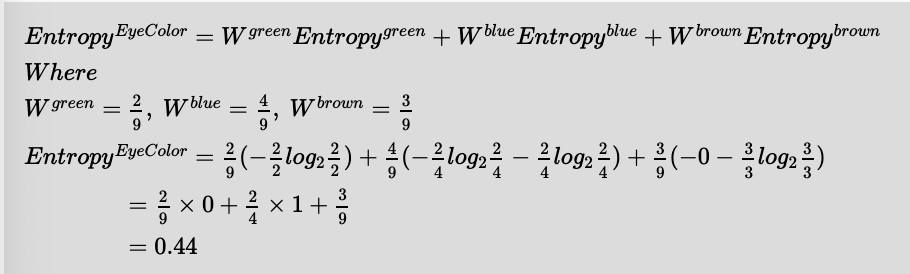
Now let's evaluate the training set on the feature 'PlayCricket' (Remember we are still evaluating the features, and haven't commited to a split using a specific feature yet). As before we can compute the relevant entropies as shown below:
Feature (PlayCricket)
| |
Play = 6 NoPlay = 3
(A=4,B=2) (A=0,B=3)

Now let's evaluate the training set on the 'Education' feature.
Feature (Education)
| |
UG = 4 PG = 5
(A=3,B=1) (A=1,B=4)
Unlike the other feature, this would yield two impure nodes. Therefore it's unlikely that this feature would give us a better InformationGain.
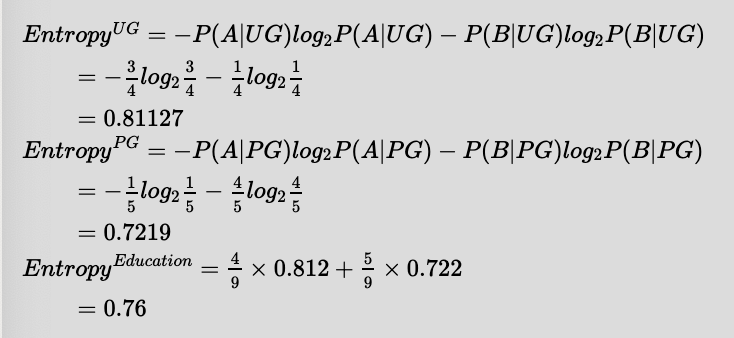
Now that we have evaluated all the features available, lets compute what feature yields the maximum InformationGain.
InformationGain = EntropyBefore - EntropyAfter
| Feature | InformationGain |
|---|---|
| EyeColor | 0.99 - 0.44 |
| Play | 0.99 - 0.60 |
| Education | 0.99 - 0.76 |
Therefore, the best split would be made by choosing EyeColor as the feature on this node.
Now the decision tree so far would look as below:
Feature (EyeColor)
____________|______________
| | |
Green = 2 Blue = 4 Brown = 3
(A=2,B=0) (A=2,B=2) (A=0,B=3)
Green and Brown Nodes have a pure split each and they couldn't be split any further, as such they form leaves. Blue node is impure, so we evaluate the features again for a best split.
Let's draw the potential decision tree with each feature and decide which feature to evaluate first.
With Education feature, we get the following tree. If we choose this feature, it would yield one leaf and an impure node, which needs splitting further.
Feature (EyeColor)
____________|______________
| | |
Green = 2 Blue = 4 Brown = 3
(A=2,B=0) (A=2,B=2) (A=0,B=3)
|
Education
-----------------
| |
UG = 1 PG = 3
(A=1,B=0) (A=1,B=2)
With PlayCricket feature, we get the following tree. If we choose this feature, it would yield two leaves as the splits would be pure as shown. Therefore the best choice would be to split the node with PlayCricket feature.
Feature (EyeColor)
____________|______________
| | |
Green = 2 Blue = 4 Brown = 3
(A=2,B=0) (A=2,B=2) (A=0,B=3)
|
Feature(PlayCricket)
-----------------
| |
Play = 2 NoPlay = 2
(A=2,B=0) (A=0,B=2)
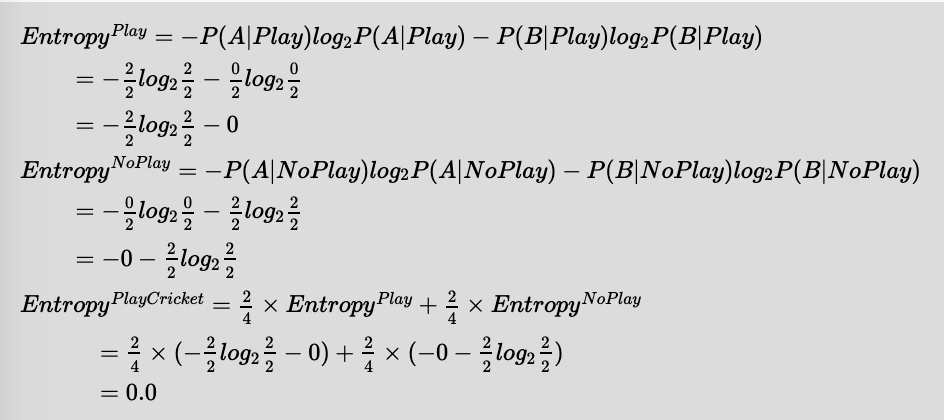
Choosing PlayCricket feature on this node would yield the maximum InformationGain, therefore no need to evaluate the rest of the features (i.e. Education). As we have partitioned the whole training set into pure nodes by choosing appropriate features at each node, the training must stop now.
Testing
[To Do] #References